
Virtual machine
Journaux liées à cette note :
Certification HDS : ce que j'ai appris en creusant pour un ami
Un ami, professionnel libéral de santé, a vibe codé une application de gestion pour ses patients actuellement hébergée sur Supabase. Il souhaite migrer vers un Hébergeur de Données de Santé — il a notamment vu que Scaleway propose des services certifiés HDS — et m'a demandé si je connaissais un développeur pour l'accompagner dans ce projet.
J'ai croisé la notion de HDS pour la première fois en 2016, chez Tech-Angels. Depuis, j'ai suivi le sujet de loin sans jamais creuser.
Je profite de sa demande pour étudier le sujet en profondeur avant de lui répondre, et publier une note de ce que j'aurai appris.
Hébergeur de Données de Santé, c'est quoi ?
Toute personne physique ou morale qui héberge des données de santé à caractère personnel recueillies à l’occasion d’activités de prévention, de diagnostic, de soins ou de suivi médico-social pour le compte de personnes physiques ou morales à l'origine de la production ou du recueil de ces données ou pour le compte du patient lui-même, doit être agréée ou certifiée à cet effet.
Texte de loi : article L.1111-8 du Code de la santé publique
Qu'est-ce qu'une donnée de santé (DDS) ?
Avant d'aller plus loin, j'ai eu besoin de comprendre précisément ce qu'est une "donnée de santé".
La CNIL distingue trois catégories (source) :
- Les données de santé par nature : antécédents médicaux, diagnostics, traitements, résultats d'examens, ordonnances, comptes-rendus d'hospitalisation.
- Les données qui deviennent des données de santé par croisement : le poids ou le nombre de pas seuls ne le sont pas, mais croisés avec d'autres mesures (tension artérielle, apports caloriques), ils le deviennent.
- Les données qui deviennent des données de santé par leur usage : un rendez-vous chez un médecin, à lui seul, n'est pas une donnée de santé — mais le motif de la consultation, si.
Concrètement, dans l'application de mon ami, cela inclut probablement les noms des patients, leurs comptes-rendus, leurs ordonnances, les notes de suivi, et potentiellement les créneaux de rendez-vous liés à des actes de soins. Ce n'est pas seulement la « base médicale » au sens strict — c'est tout ce qui, relié à une personne identifiée, révèle qu'elle a reçu ou consulté pour des soins.
Un document médical sans identifiant, est-ce encore une donnée de santé ?
Une question qui m'est tout de suite venue à l'esprit : un document médical sans identifiant — pas de nom, pas de numéro de patient — est-ce encore une donnée de santé ?
La réponse dépend de la possibilité de ré-identification. Si le document est véritablement anonymisé, qu'il n'existe aucun moyen raisonnable de le relier à une personne, alors ce n'est plus une donnée de santé à caractère personnel — ça sort du périmètre du RGPD et du HDS.
Mais en pratique, c'est très difficile de le rendre vraiment anonyme. Un diagnostic rare, une date de traitement, ou un hôpital spécifique croisés avec d'autres sources, peuvent permettre de ré-identifier la personne.
La CNIL considère qu'une donnée est « personnelle » dès qu'il existe des « moyens raisonnablement susceptibles » de ré-identification.
Je pense qu'une bonne méthode pour estimer si c'est une DDS ou non, est de se mettre dans la peau d'un détective privé : si on me donnait ce document et tous les indices disponibles (date, hôpital, pathologie rare…), est-ce que je pourrais remonter à la personne ? Si la réponse est oui, c'est une donnée de santé. La question n'est donc pas « y a-t-il un nom dans le document ? » mais « quelqu'un, avec les moyens raisonnables, pourrait-il retrouver à qui ça appartient ? ».
Quels liens entre PII et DDS ?
Pour faire le lien avec les PII : toute Données de santé (DDS) est une PII, mais l'inverse n'est pas vrai. Un nom, une adresse email ou une adresse IP sont des PII parce qu'ils permettent d'identifier une personne.
Une donnée de santé est une PII qui révèle en plus quelque chose sur l'état de santé de cette personne. La distinction importe parce que le régime juridique n'est pas le même : les DDS sont soumises au RGPD comme les PII, mais avec des protections supplémentaires — secret médical, consentement explicite, obligation d'hébergement certifié HDS.
Qui est le "responsable de traitement" ?
Pour comprendre à qui s'applique la certification HDS, j'ai eu besoin de creuser la notion de "responsable de traitement" au sens du RGPD. Je croise ce terme régulièrement, je pense le comprendre dans les grandes lignes, mais j'ai voulu comprendre précisément où se situent les frontières.
D'après ce que j'ai compris, le responsable de traitement est la personne morale (ou la personne physique en entreprise individuelle) qui décide quoi faire avec les données personnelles. C'est elle qui détermine pourquoi on collecte les données et comment on les traite. Ce n'est pas l'individu (le médecin, l'infirmière) — c'est la structure juridique qui a la relation de soin avec le patient.
Concrètement :
| Situation | Responsable de traitement | Pourquoi ? |
|---|---|---|
| Médecin salarié à l'hôpital | L'hôpital (personne morale) | C'est l'hôpital qui a la relation avec le patient, pas le médecin individuellement |
| Médecin dans un cabinet en SARL | La SARL (personne morale) | C'est la SARL qui signe les contrats et est responsable en cas de fuite |
| Médecin libéral en entreprise individuelle | Le médecin (personne physique) | Il n'y a pas de structure intermédiaire |
| Cabinet médical | Le cabinet (personne morale) | Le cabinet détermine les règles de gestion du système d'information |
| Doctolib | Non — c'est un sous-traitant | Doctolib est un moyen de communication entre le médecin et le patient, comme un téléphone amélioré |
| Scaleway | Non — c'est un hébergeur | Scaleway fournit l'infrastructure, il ne traite pas les données pour ses propres fins |
| Un développeur freelance qui maintient le serveur | Non — c'est un sous-traitant | Il administre l'infrastructure pour le compte du responsable de traitement |
Cette distinction est cruciale pour comprendre la certification HDS. La loi dit que l'hébergement doit être certifié quand il est fait "pour le compte de" un responsable de traitement. Si tu es toi-même le responsable de traitement, tu n'héberges pas pour un tiers — tu héberges pour toi-même alors pas besoin de certification HDS (mais tu restes soumis au RGPD).
C'est pour ça qu'un médecin qui gère son propre dossier patient n'a pas besoin de HDS, mais qu'un hébergeur qui stocke les données pour le compte de ce médecin doit être certifié.
Un cas limite : les services médicaux numériques
Le cas des services médicaux numériques comme Poppins — "le dispositif médical numérique à domicile pour les enfants dyslexiques" — est compliqué. Qui est le responsable de traitement ?
La réponse dépend de qui décide quoi faire avec les données :
- Si Poppins décide quelles données collecter et comment les utiliser (recherche, amélioration du produit) alors Poppins est responsable de traitement
- Si l'orthophoniste décide quelles données utiliser pour le suivi du patient alors l'orthophoniste est responsable de traitement
- Si les deux ont un rôle de décision → co-responsabilité (article 26 RGPD)
Où est la documentation officielle HDS ?
La documentation officielle est trouvable sur le site https://esante.gouv.fr/ => "Produits et services" => "HDS" => "Les référentiels de la procédure de certification".
La documentation HDS est nommée "référentiel de certifications HDS", elle est disponible au format PDF à cette adresse https://esante.gouv.fr/sites/default/files/media_entity/documents/referentiel_certification_hds---fr--v2.pdf.
Je n'ai pas trouvé de version HTML de ce document.
D'après ce que j'ai compris, ce sont des personnes de l'Agence du Numérique en Santé (ANS) qui ont rédigé les 29 pages du référentiel de certifications HDS.
Ce référentiel a été officialisé dans le Journal Officiel le 16 mai 2024 https://www.legifrance.gouv.fr/jorf/id/JORFTEXT000049537692 par un ministre délégué à la santé. Ce document remplace la version précédente de 2018.
Et voici le communiqué de presse de l'ANS : Publication au Journal Officiel du référentiel de certification HDS : souveraineté des données et améliorations du référentiel.
Je suis ravi de lire la section Focus sur l’ajout d’exigences relatives à la souveraineté des données qui indique :
L’hébergement physique des données de santé doit être réalisé exclusivement sur le territoire d’un pays situé au sein de l’Espace Economique Européen.
🙂
Les 6 activités du référentiel HDS
Est considérée comme une activité d'hébergement de données de santé à caractère personnel sur support numérique ... des activités suivantes :
- La mise à disposition et le maintien en condition opérationnelle de sites physiques permettant d'héberger l'infrastructure matérielle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure matérielle du système d'information utilisé pour le traitement de données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure virtuelle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de la plateforme d'hébergement d'applications du système d'information ;
- L'administration et l'exploitation du système d'information contenant les données de santé ;
- La sauvegarde des données de santé
Cette liste, reformulée en activités concrètes :
| # | Activité |
|---|---|
| 1 | Gestion des sites physiques : datacenters, baies serveurs, climatisation, alimentation électrique, sécurité des locaux |
| 2 | Gestion de l'infrastructure matérielle : serveurs physiques, stockage, câblage réseau, commutation |
| 3 | Gestion de l'infrastructure virtuelle : machines virtuelles, réseaux virtuels, stockage virtuel, hyperviseurs |
| 4 | Gestion de la plateforme applicative : bases de données managées, conteneurs, serveurs d'application |
| 5 | Gestion des sauvegardes : sauvegardes automatisées, stockage hors site, restauration |
| 6 | Administration et exploitation du SI : supervision, mises à jour, gestion des accès, support technique, astreinte |
Il y a un point important que j'ai mis du temps à saisir : l'obligation de certification ne s'applique qu'à l'hébergement de données de santé pour un tiers qui est responsable de traitement.
Par conséquent, un professionnel de santé qui auto-héberge ses propres données n'a pas besoin de certification HDS pour les activités de cette liste qu'il administre lui-même.
Un exemple concret
Imaginons un cabinet de médecin, qui développe une application web qui contient des données de santé. Cette application est à destination de ses utilisateurs finaux, ses patients.
L'application web est codée en JavaScript avec PostgreSQL pour la persistance des données.
Pour le déploiement, le développeur employé directement par le cabinet de médecin fait le choix de déployer le tout sur une Virtual machine Scaleway.
D'après la version du 18 juin 2026 de la page "L’hébergement des données de santé et la certification HDS" de la documentation Scaleway, voici la liste des services certifiés HDS :

Les composants de fondations les plus importants sont bien certifiés. Je note au passage que l'offre "Managed Database for PostgreSQL and MySQL" n'est pas certifiée pour le moment.
Ceci n'est pas grave dans mon exemple si je déploie directement une image Docker de PostgreSQL directement sur la Virtual machine. Les sauvegardes peuvent être déposées dans Scaleway Object Storage qui lui est certifié.
Le cabinet de médecin devra souscrire un plan de support niveau Business à 250 € par mois pour pouvoir ensuite signer un contrat HDS :

Ensuite, Scaleway remettra au cabinet de médecin (son client) un document de garantie HDS, conformément au chapitre 8 du référentiel :
Voici à quoi pourrait ressembler ce document : "Exemple fictif d'une garantie de certification HDS de Scaleway".
Ensuite, les DevOps salariés directement du cabinet de santé déploient, maintiennent, administrent l'application sur les Virtual machine de Scaleway sans que le cabinet de médecin n'ait besoin de certification HDS car il n'est pas un hébergeur de données parce qu'il ne vend pas son service à d'autres professionnels. Seuls les patients directs utilisent son service.
Employé vs freelance : une distinction absurde mais légale
Il y a un point que j'ai mis du temps à saisir, et qui me paraît absurde mais qui est juridiquement cohérent.
Un employé (CDD ou CDI) du cabinet de santé qui gère le serveur, fait les mises à jour et les sauvegardes n'a pas besoin de certification HDS. Il fait partie de l'organisation du responsable de traitement — il n'est pas un sous-traitant.
Le même développeur, faisant exactement le même travail (SSH, mises à jour, sauvegardes), mais en freelance vendant 5 heures de prestation, a besoin de la certification HDS pour l'activité 5 (administration et exploitation). Pourquoi ? Parce qu'il est une entité séparée, un sous-traitant au sens RGPD, qui assure une activité d'hébergement pour le compte d'un tiers responsable de traitement.
La distinction ne se fait pas sur la nature du travail, mais sur le statut juridique de la personne qui le fait :
- Employé du cabinet (CDD/CDI) avec accès SSH → pas de HDS, il fait partie du responsable de traitement
- Freelance avec accès SSH permanent → HDS requis, il est sous-traitant et assure l'activité 5
Le cas du freelance qui livrerait uniquement du code
Si le freelance se contente de fournir du code — application, scripts d'infrastructure, configs de déploiement — et qu'il push tout dans un repo Git sans jamais avoir accès au serveur, à la base de données ni aux données, alors il n'assure aucune des 6 activités d'hébergement. Il livre un produit (du code), il n'opère pas un service.
Le test légal reste le même : "le fait d'assurer pour le compte du responsable de traitement tout ou partie des activités suivantes." Le verbe clé est "assurer" — c'est-à-dire exécuter, opérer, maintenir en condition opérationnelle. Les 6 activités décrivent des opérations sur l'infrastructure et le système, pas de la production de code.
La frontière se joue sur un point précis : qui appuie sur le bouton "déployer" ?
- Si c'est un employé du cabinet de santé qui contrôle l'outil de déploiement (par exemple ArgoCD) et déclenche les déploiements → freelance = livreur de code → pas de HDS
- Si le freelance a accès à cet outil et déclenche lui-même les déploiements → il participe à l'exploitation (activité 5) → HDS requis
Combien coûte une certification HDS pour les activités 4, 5 et 6 ?
J'ai cherché le processus officiel pour obtenir la certification HDS, voici ce que j'ai retenu :
- Mettre en place un Système de Management de la Sécurité de l'Information (SMSI) conforme à ISO 27001 (politique de sécurité, analyse de risques, gestion des accès, plan de continuité) — prérequis obligatoire.
- Choisir un organisme certificateur accrédité Comité français d'accréditation (Cofrac) (BSI, AFNOR, Bureau Veritas, LRQA…).
- Audit sur site en deux volets : conformité ISO 27001, puis exigences HDS spécifiques.
- Correction des non-conformités relevées.
- Obtention du certificat (valable 3 ans, avec audit de surveillance annuel).
J'ai volontairement laissé de côté le contenu concret du SMSI et de la norme ISO 27001 — je les connais mal. Cette note m'a donné envie d'explorer le sujet en profondeur, mais je le ferai dans une note séparée pour ne pas allonger encore celle-ci.
Les coûts typiques pour une TPE (< 10 personnes) :
| Poste | Estimation |
|---|---|
| Mise en place SMSI (conseil externe) | 2 000 – 6 000 € |
| Audit initial COFRAC (ISO 27001 + HDS) | 8 000 – 15 000 € |
| Audits de surveillance annuels (×2) | 2 000 – 5 000 € |
| Sous-total coûts externes | 12 000 – 26 000 € |
| Coût interne du salarié (100 – 200 h à 500 €/j soit ~70 €/h super brut) | 7 000 – 14 000 € |
| Total sur 3 ans | 19 000 – 40 000 € |
Estimation en temps humain (pour une personne seule, en charge de tout) :
| Étape | Effort humain estimé | Durée calendrier estimée |
|---|---|---|
| Mise en place SMSI (rédaction, procédures, analyse de risques, choix des outils) | 40 – 100 heures | 2 – 4 mois |
| Choix du certificateur et préparation du dossier | 15 – 30 heures | 3 – 6 semaines |
| Audit initial (sur site + préparation) | 15 – 30 heures | 1 – 2 semaines |
| Correction des non-conformités | 20 – 60 heures | 2 – 6 semaines |
| Obtention du certificat + 1er audit de surveillance | 10 – 30 heures | 1 – 2 mois |
| Total (avec SMSI ou maturité existante) | 100 – 250 heures | 6 – 9 mois |
| Total (sans SMSI préalable) | 200 – 400 heures | 12 – 18 mois |
Sources
Les fourchettes de coûts et de durées ci-dessus sont des estimations de Fermi calculées par MiMO-V2-Pro, recalibrées pour coller aux données publiées :
- Legiscope — Certification HDS hébergeur de données de santé 2026 (Dr. Thiébaut Devergranne, 23 mai 2026) : fourchette de 20 000 à 35 000 € sur 3 ans pour une TPE. Durée de 6 à 9 mois si l'organisation dispose déjà d'un SMSI ou d'une maturité ISO 27001 ; 12 à 18 mois sans SMSI préalable (dont 9-12 mois pour la certification ISO 27001 seule).
- Galeon — Certification HDS en 2026 (21 avril 2026) : « Les audits représentent généralement plusieurs dizaines de milliers d'euros, auxquels s'ajoutent les coûts internes de préparation et de mise en conformité. »
Je pense que des outils de service d'automatisation de conformité du type Oneleet que j'ai testés, peuvent accélérer le processus de mise en place d'un SMSI pour obtenir une certification ISO 27001.
Le risque sécurité du code vibe codé
Ça me fait un peu peur, honnêtement. Mon ami a vibe codé une application qui contient des données de santé. Et payer les frais importants d'une agence de développeur certifiée HDS n'aurait aucun sens dans ce contexte d'une application amateur sur mesure.
Qu'est-ce que je vais répondre à mon ami ?
D'abord, son idée d'hébergement chez Scaleway va coûter cher ! Déjà 250 € par mois rien que pour le plan de support Business.
Pour éviter cela, une solution serait d'auto-héberger l'application chez soi, dans son bureau, sur un petit serveur. Tant qu'on n'héberge pas pour un tiers, il n'y a pas besoin de certification HDS.
Mais il ne pourra pas demander à un développeur freelance d'administrer ce serveur. Dès qu'un freelance intervient sur l'infrastructure (accès SSH, mises à jour, sauvegardes), il assure l'activité 5 du référentiel HDS — et il devrait être certifié ! Et le coût de la certification pour administrer ce serveur, pour une seule instance, sera bien trop élevé.
Autre solution : embaucher un développeur en CDD pour toute intervention. C'est légalement possible sans HDS, mais c'est lourd à gérer et coûteux.
Réflexion sur le Vibe coding : libération ou prolétarisation ?
En tant qu'artisan développeur, je trouve amusant d'observer plusieurs de mes amis vibe coder des applications sur mesure pour leur besoin.
Pour le moment je n'ai pas cherché à savoir s'ils essaient de comprendre le code produit, ou si le code reste une boîte noire dont ils se fichent tant que ça marche. Mais c'est un phénomène socialement intéressant, et je ne sais pas si c'est une bonne nouvelle ou non.
Si le vibe coding reste un outil d'appropriation, si la personne comprend ce qu'elle fait, peut modifier, adapter, expliquer — alors c'est un acte de déprolétarisation : il reprend le contrôle sur ses outils de travail.
Mais si le code reste opaque, s'il ne s'agit que de produire sans comprendre, alors le vibe coding n'est qu'une nouvelle forme de prolétarisation. Le savoir ne passe plus par la machine au sens de Bernard Stiegler — il passe par l'IA, et la personne reste aussi démunie que devant si l'outil disparaît ou change, c'est de la désindividuation au sens de Bernard Stiegler. La personne n'a pas acquis de savoir, elle a acquis un résultat, elle "consomme".
C'est ce qui fait de ces outils des pharmakons : ils peuvent désindividuer autant qu'ils peuvent aider à s'individuer, selon l'usage qu'on en fait.
J'ai développé cette réflexion dans "J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes" et dans "Ma lutte contre mon affaiblissement cognitif". En résumé, j'essaie personnellement d'éviter cette prolétarisation : plutôt que de consommer l'IA pour produire des choses, j'essaie de groker — comprendre en profondeur, pas seulement obtenir un résultat.
Comment j'ai perdu ma discipline en décembre et janvier
Jusqu'à mi-décembre 2025, cela faisait environ 2 ans que j'arrivais à rester concentré sur un sujet à la fois. J'avais réussi à éviter de papillonner d'un sujet à l'autre. Pour moi, un sujet n'est vraiment terminé que lorsque j'ai publié la note correspondante.
Le dernier sujet que j'avais exploré avec succès était mon étude de Fedora CoreOS.
Je me suis ensuite lancé dans l'étude pratique approfondie de Podman Quadlets. J'ai réussi à publier coreos-quadlet-playground, mais avant même d'avoir commencé à rédiger ma note de synthèse, j'ai perdu ma discipline.
Dans cette note, je vais tenter d'expliquer comment et pourquoi j'ai "dérapé" et faire un bilan des side-projects sur lesquels j'ai papillonné pendant ces deux derniers mois (depuis mi-décembre).
Lors de mon travail sur Podman Quadlets, j'ai découvert comment ce projet utilise avec élégance systemd-run et le mécanisme des generators (systemd-run-generator) de systemd pour incarner la philosophie Unix.
Suite à cette découverte, j'ai repensé aux scripts manuels que j'utilisais ces derniers mois pour lancer mes VM QEMU. Exemple : up-qemu-vm.sh. Je me suis dit qu'il serait élégant de lancer des VM QEMU de la même manière que Podman Quadlets.
Je n'ai pas réussi à résister à cette idée. Le 10 décembre au soir, je me suis dit que j'allais consacrer une petite heure à tester cette idée via du vibe coding avec Aider et Claude Sonnet 4.5.
Cette heure s'est transformée en 12h de session non-stop. J'ai réussi à publier une première version de qemu-compose, mais je venais de rompre ma discipline : je n'avais toujours pas écrit ma note sur Podman Quadlets.
Depuis, je n'ai pas réussi à retrouver ma discipline. Je suis tombé dans une spirale de papillonnage qui a duré deux mois 🙈.
En rédigeant cette note, j'ai essayé de comprendre pourquoi j'avais dérapé.
Je pense que c'était la combinaison de plusieurs facteurs :
- Le déclencheur : Ma première expérience réelle de vibe coding sur un projet complet. Cette expérience m'a tellement excité et en même temps tellement perturbé que j'ai perdu la motivation de rédiger ma note sur Podman Quadlets.
- La cascade : Une fois le premier écart fait, l'effet "What the hell" s'est enclenché : mon cerveau a rationalisé la continuation du comportement déviant par un "de toute façon, c'est déjà foutu, autant continuer".
- Le contexte : J'étais dans une période de stress et de frustration. L'illusion de toute-puissance qu'offrent les derniers modèles 4.5 d'Anthropic — obtenir des résultats rapides — m'a poussé dans une fuite en avant, un échappatoire pour combler mes frustrations du moment.
Depuis 2 ans, j'utilise trois garde-fous (circuit breakers) pour m'empêcher de démarrer un nouveau projet sans avoir terminé le précédent — autrement dit, pour éviter de papillonner et de survoler les sujets :
- Je tracke toutes mes activités via Toggl. Quand je démarre une activité, je lance consciemment le chronomètre. Cette friction me force à nommer ce que je fais et à rester conscient du temps que j'y consacre. C'est un premier filtre contre les distractions impulsives.
- Tous les matins, je rédige mes todo lists pro et perso dans Obsidian. L'élément clé est une section "Je ne veux pas faire" où je liste explicitement les tâches tentantes mais hors priorité. C'est mon exutoire pour les idées qui me donnent envie sans pour autant y céder.
- La publication de notes sur notes.sklein.xyz me force à définir ma "Definition of Done". Une itération (un sujet) n'est terminée que quand la note est publiée.
En analysant mes notes, je constate que j'ai progressivement abandonné la rédaction de mes todo lists quotidiennes à partir du 5 décembre — soit 5 jours avant mon dérapage sur qemu-compose.
Je pense que ce n'est pas un hasard.
#JaiDécidé de reprendre cette routine dès demain. C'est mon garde-fou le plus important.
Voici les sujets en vrac que j'ai survolés pendant ces 2 derniers mois — tous sans note de synthèse publiée :
- Réimplémentation complète de ma configuration chezmoi (inachevée)
- Développement de
gnome-settings-import-export
- Développement de
- Étude de timeshift et snapper
- Installation et configuration de netbird sur mes NUC
- Tentative d'installation de Kodi sur un de mes NUC (inachevée)
- Nouvelle configuration Neovim from scratch basée sur LazyVim (inachevée) :
lazyvim-playground - Migration de Fugitive vers Neogit
- Développement et publication du plugin
neo-tree-session.nvim - Étude puis abandon d'une migration Alacritty + tmux → wezterm (branche WIP)
- Étude puis abandon d'une migration Alacritty + tmux → kitty
- Étude d'une migration Alacritty → foot + tmux (en cours)
- Contribution au projet foot avec 2 Merge Requests :
- Test d'avante.nvim, notamment Avante Zen Mode — piste abandonnée
- Migration de Aider vers OpenCode
- Adoption de Jujutsu à la place de Git — utilisation quotidienne depuis plus d'un mois, progression continue mais pas encore fluide
Bilan : 13 explorations, 2 contributions open source, 1 plugin publié, 0 note de synthèse 😔.
En publiant cette note, je souhaite casser cet effet "What the hell".
Je vais sans doute accepter de ne pas publier de notes sur les sujets que j'ai abandonnés. Par contre, je souhaite à l'avenir publier des notes au sujet de :
Est-ce qu'une fonction Open WebUI peut importer une autre fonction Open WebUI ?
J'ai essayé de comprendre si une fonction Open WebUI pouvait importer le code d'une autre fonction Open WebUI.
La réponse est non. Je vais tenter dans cette note d'expliquer pourquoi.
(j'ai aussi publié une version de cette note en anglais dans la section "discussions" de Open WebUI)
Open WebUI propose de méthode pour créer ou mettre à jour une fonction Open WebUI sur une instance en production : via l'interface web d'administration, ou via l'API REST.
Une instance production fait référence à Open WebUI hébergé sur une Virtual machine ou un Cluster Kubernetes, par opposition à une instance locale lancée en mode développement.
Dans un premier temps, j'ai essayé d'importer dans Open WebUI les deux fichiers suivants :
# utils.py
def add(a, b):
return a + b
# hello_world.py
from pydantic import BaseModel, Field
from .utils import add
class Pipe:
class Valves(BaseModel):
pass
def __init__(self):
self.valves = self.Valves()
def pipe(self, body: dict):
print("body", body)
return f"Hello, World! {add(1, 2)}"
Le fichier hello_world.py contient un import de utils.add implémenté dans le premier fichier.
L'importation du premier fichier est refusée par Open WebUI parce que class Pipe: est absent de utils.py.
J'ai ensuite trompé Open WebUI en ajoutant une classe Pipe fictive das le fichier utils.py et l'importation a réussi.
Ensuite l'import de hello_world.py a échoué parce que Open WebUI n'arrive pas a effectué l'import from .utils import add. J'ai ensuite effectué plusieurs tentatives d'import absolut, par exemple from open_webui.utils import add… mais sans succès.
J'ai pris un peu de temps pour étudier l'implémentation d'Open WebUI et j'ai identifié cette section de code :
module_name = f"tool_{tool_id}"
module = types.ModuleType(module_name)
sys.modules[module_name] = module
Ce code permet à Open WebUI de charger dynamiquement le code source des modules qui sont stockés dans la base de données.
Un esprit tordu pourrait en pratique importer une fonction chargé dynamiquement dans un autre module dynamique, par exemple :
from tool_utils import add
Mais cette méthode ne correspond pas à l'usage normal d'Open WebUI.
Pour implémenter des fonctions "modulaires", Open WebUI conseille d'utiliser la fonctionnalité "Pipelines" :
Welcome to Pipelines, an Open WebUI initiative. Pipelines bring modular, customizable workflows to any UI client supporting OpenAI API specs – and much more! Easily extend functionalities, integrate unique logic, and create dynamic workflows with just a few lines of code.
Pour les personnes qui souhaitent vraiment effectuer des imports dans des fonctions Open WebUI sans utiliser la fonction Pipelines, il existe tout de même une solution que j'ai implémentée dans la branche test-if-openwebui-function-support-import.
Voici le contenu de /functions/hello_world.py :
from pydantic import BaseModel, Field
from open_webui.shared.utils import add
class Pipe:
class Valves(BaseModel):
pass
def __init__(self):
self.valves = self.Valves()
def pipe(self, body: dict):
print("body", body)
return f"Hello, World! {add(1, 2)}"
Le contenu de /shared/utils.py
def add(a, b):
return a + b
Pour rendre accessible /shared/utils.py dans l'instance d'Open WebUI lancé loculement, j'ai configuré de volume mounts suivante dans mon /docker-compose.yml :
openwebui:
image: ghcr.io/open-webui/open-webui:0.6.15
restart: unless-stopped
volumes:
- ./shared/:/app/backend/open_webui/shared/
ports:
- "3000:8080"
Ensuite, si je souhaite pouvoir déployer en production cette fonction Open WebUI et le module utils.py, il sera nécessaire de build une image Docker customisé d'Open WebUI pour y inclure le fichier /shared/utils.py.
Cette méthode peut fonctionner, mais cela reste un "hack" non conseillé. Il est préférable d'utiliser la méthode "Pipelines".
Faut-il encore configurer du swap en 2025, même sur des serveurs avec beaucoup de RAM ?
Aujourd'hui, j'ai implémenté des tests de montée en charge à l'aide de Grafana k6. En ciblant un site web hébergé sur un petit serveur Scaleway DEV1-M, j'ai constaté que le serveur est devenu inaccessible à la fin des tests. Aucun swap n'était configuré sur cette Virtual machine de 4Go de RAM.
Je me suis souvenu qu'en 2019, j'ai rencontré aussi des problèmes de freeze sur une VM AWS EC2 que j'ai corrigés en ajoutant un peu de swap au serveur. Après cela, je n'ai constaté plus aucun freeze de VM pendant 4 ans.
Ce sujet de swap m'a fait penser à la question qu'un ami m'a posée en octobre 2024 :
Désactiver le swap sur une Debian, recommandé ou pas ?
Alors que j'ai 29Go utilisé sur 64, le swap était plein (3,5Go occupé à 100%), les 12 cœurs du serveur partaient dans les tours. J'ai désactivé le swap et me voilà gentiment avec un load average raisonnable, pour les tâches de cette machine.
C'est une très bonne question que je me pose depuis longtemps. J'ai enfin pris un peu de temps pour creuser ce sujet.
Sept mois plus tard, voici ma réponse dans cette note 😉.
#JaiDécouvert le paramètre kernel nommé Swappiness.
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
Dans la documentation SwapFaq d'Ubuntu j'ai lu :
The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. Because disks are much slower than RAM, this can lead to slower response times for system and applications if processes are too aggressively moved out of memory.
- swappiness can have a value of between
0and100swappiness=0tells the kernel to avoid swapping processes out of physical memory for as long as possibleswappiness=100tells the kernel to aggressively swap processes out of physical memory and move them to swap cacheThe default setting in Ubuntu is
swappiness=60. Reducing the default value of swappiness will probably improve overall performance for a typical Ubuntu desktop installation. A value ofswappiness=10is recommended, but feel free to experiment. Note: Ubuntu server installations have different performance requirements to desktop systems, and the default value of60is likely more suitable.
D'après ce que j'ai compris, plus swappiness tend vers zéro, moins le swap est utilisé.
J'ai lu ici :
vm.swappiness = 60: Valeur par défaut de Linux : à partir de 40% d’occupation de Ram, le noyau écrit sur le disque.
Cependant, je n'ai pas trouvé d'autres sources qui confirment cette correspondance entre la valeur de swappiness et un pourcentage précis d'utilisation de la RAM.
J'ai ensuite cherché à savoir si c'était encore pertinent de configurer du swap en 2025, sur des serveurs qui disposent de beaucoup de RAM.
#JaiLu ce thread : "Do I need swap space if I have more than enough amount of RAM?", et voici un extrait qui peut servir de conclusion :
In other words, by disabling swap you gain nothing, but you limit the operation system's number of useful options in dealing with a memory request. Which might not be, but very possibly may be a disadvantage (and will never be an advantage).
Je pense que ceci est d'autant plus vrai si le paramètre swappiness est bien configuré.
Concernant la taille du swap recommandée par rapport à la RAM du serveur, la documentation de Ubuntu conseille les ratios suivants :
RAM Swap Maximum Swap 256MB 256MB 512MB 512MB 512MB 1024MB 1024MB 1024MB 2048MB 1GB 1GB 2GB 2GB 1GB 4GB 3GB 2GB 6GB 4GB 2GB 8GB 5GB 2GB 10GB 6GB 2GB 12GB 8GB 3GB 16GB 12GB 3GB 24GB 16GB 4GB 32GB 24GB 5GB 48GB 32GB 6GB 64GB 64GB 8GB 128GB 128GB 11GB 256GB 256GB 16GB 512GB 512GB 23GB 1TB 1TB 32GB 2TB 2TB 46GB 4TB 4TB 64GB 8TB 8TB 91GB 16TB
#JaiDécouvert aussi que depuis le kernel 2.6, les fichiers de swap sont aussi rapides que les partitions de swap :
Definitely not. With the 2.6 kernel, "a swap file is just as fast as a swap partition."
Suite à ces apprentissages, j'ai configuré et activé un swap de 2G sur la VM Scaleway DEV1-L équipée de 4G de RAM, avec le paramètre swappiness réglé à 10.
J'ai relancé mon test Grafana k6 et je n'ai constaté plus aucun freeze, je n'ai pas perdu l'accès au serveur.
De plus, probablement grâce au paramètre swappiness fixé à 10, j'ai observé que le swap n'a pas été utilisé pendant le test.
Suite à ces lectures et à cette expérience concluante, j'ai décidé de désormais configurer systématiquement du swap sur tous mes serveurs de la manière suivante :
if swapon --show | grep -q "^/swapfile"; then
echo "Swap is already configured"
else
get_swap_size() {
local ram_gb=$(free -g | awk '/^Mem:/ {print $2}')
# Why this values? See https://help.ubuntu.com/community/SwapFaq#How_much_swap_do_I_need.3F
if [ $ram_gb -le 1 ]; then
echo "1G"
elif [ $ram_gb -le 2 ]; then
echo "1G"
elif [ $ram_gb -le 6 ]; then
echo "2G"
elif [ $ram_gb -le 12 ]; then
echo "3G"
elif [ $ram_gb -le 16 ]; then
echo "4G"
elif [ $ram_gb -le 24 ]; then
echo "5G"
elif [ $ram_gb -le 32 ]; then
echo "6G"
elif [ $ram_gb -le 64 ]; then
echo "8G"
elif [ $ram_gb -le 128 ]; then
echo "11G"
else
echo "11G"
fi
}
SWAP_SIZE=$(get_swap_size)
fallocate -l $SWAP_SIZE /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
if ! grep -q "^/swapfile.*swap" /etc/fstab; then
echo "/swapfile none swap sw 0 0" >> /etc/fstab
fi
fi
# Why 10 instead default 60? see https://help.ubuntu.com/community/SwapFaq#:~:text=a%20value%20of%20swappiness%3D10%20is%20recommended
echo 10 | tee /proc/sys/vm/swappiness
echo "vm.swappiness=10" | tee -a /etc/sysctl.conf
Journal du dimanche 09 mars 2025 à 10:37
Je viens de publier le playground suivant : qemu-fedora-workstation-playground.
Je suis particulièrement satisfait d'avoir mis en place ce playground, car il concrétise plusieurs objectifs que je m'étais fixés depuis longtemps :
- Cela fait plusieurs années que je souhaite à remplacer Vagrant par une solution plus minimaliste. Je souhaite réduire mon utilisation d'outils basés sur Ruby.
J'ai, par exemple, effectué une tentative en février 2023 basée sur virsh. - Utiliser une VM Fedora Workstation pour tester ma configuration dotfiles basée sur chezmoi :
- Par exemple ici
- et ici : How do you test your configuration on a bare OS? Docker? Distrobox? Vagrant?
Finalement, la solution était assez simple à mettre en place et elle est très performante.
Ma VM Fedora Workstation affiche l'écran d'ouverture de session GNOME Display Manager en moins de 19s.
Voici une traduction en français de qemu-fedora-workstation-playground.
Voici les dépendances à installer :
$ sudo dnf install -y \
qemu-system-x86 \
qemu-system-common \
qemu-img \
qemu-img-extras \
cloud-utils \
mesa-dri-drivers \
libguestfs-tools
Pour simplifier, la méthode que je présente est basée uniquement sur QEMU.
Je télécharge la version 41 de Fedora dans sa version "cloud" :
$ wget https://download.fedoraproject.org/pub/fedora/linux/releases/41/Cloud/x86_64/images/Fedora-Cloud-Base-Generic-41-1.4.x86_64.qcow2 -O fedora-41-base.qcow2
À partir de cette image de base, je crée une image de type couche (layer) que j'utilise pour effectuer mes opérations sur la machine virtuelle. Cette approche me permet de revenir facilement en arrière (rollback) en cas de problème, annulant ainsi les modifications apportées à la VM.
$ qemu-img create -f qcow2 -b fedora-41-base.qcow2 -F qcow2 fedora-working-layer.qcow2
$ ls -s1h *.qcow2
469M fedora-41-base.qcow2
196K fedora-working-layer.qcow2
Je prépare un fichier cloud-init qui permet de configurer le mot de passe et ma clé SSH :
$ cat <<'EOF' > cloud-init.yaml
#cloud-config
users:
- name: fedora
plain_text_passwd: password
lock_passwd: false
shell: /bin/bash
sudo: ALL=(ALL) NOPASSWD:ALL
ssh_authorized_keys:
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQDEzyNFlEuHIlewK0B8B0uAc9Q3JKjzi7myUMhvtB3JmA2BqHfVHyGimuAajSkaemjvIlWZ3IFddf0UibjOfmQH57/faxcNEino+6uPRjs0pFH8sNKWAaPX1qYqOFhB3m+om0hZDeQCyZ1x1R6m+B0VJHWQ3pxFaxQvL/K+454AmIWB0b87MMHHX0UzUja5D6sHYscHo57rzJI1fc66+AFz4fcRd/z+sUsDlLSIOWfVNuzXuGpKYuG+VW9moiMTUo8gTE9Nam6V2uFwv2w3NaOs/2KL+PpbY662v+iIB2Yyl4EP1JgczShOoZkLatnw823nD1muC8tYODxVq7Xf7pM/NSCf3GPCXtxoOEqxprLapIet0uBSB4oNZhC9h7K/1MEaBGbU+E2J5/5hURYDmYXy6KZWqrK/OEf4raGqx1bsaWcONOfIVXbj3zXTUobsqSkyCkkR3hJbf39JZ8/6ONAJS/3O+wFZknFJYmaRPuaWiLZxRj5/gw01vkNVMrogOIkQtzNDB6fh2q27ghSRkAkM8EVqkW21WkpB7y16Vzva4KSZgQcFcyxUTqG414fP+/V38aCopGpqB6XjnvyRorPHXjm2ViVWbjxmBSQ9aK0+2MeKA9WmHN0QoBMVRPrN6NBa3z20z1kMQ/qlRXiDFOEkuW4C1n2KTVNd6IOGE8AufQ== contact@stephane-klein.info
ssh_pwauth: true
EOF
$ cloud-localds cloud-init.img cloud-init.yaml
Lancement de la VM avec :
- accélération graphique
- configuration d'une interface réseau virtuelle avec la redirection d'un port ssh
- partage d'un dossier entre l'hôte et la VM
$ qemu-system-x86_64 \
-m 8G \
-smp 4 \
-enable-kvm \
-drive file=fedora-working-layer.qcow2,format=qcow2 \
-device virtio-vga-gl \
-display gtk,gl=on \
-nic user,hostfwd=tcp::2222-:22 \
-drive file=cloud-init.img,format=raw \
-fsdev local,id=fsdev0,path=$(pwd)/shared/,security_model=mapped-file \
-device virtio-9p-pci,fsdev=fsdev0,mount_tag=host_share
Cette VM est accessible via ssh, comme avec Vagrant :
$ ssh-keygen -R "[localhost]:2222"
$ ssh -o StrictHostKeyChecking=no -p 2222 fedora@localhost
Warning: Permanently added '[localhost]:2222' (ED25519) to the list of known hosts.
[fedora@localhost ~]$
Et voici comment à partir de la VM je peux monter le dossier partagé :
[fedora@localhost ~]$ sudo mkdir -p /mnt/host_share
[fedora@localhost ~]$ sudo mount -t 9p -o trans=virtio,version=9p2000.L host_share /mnt/host_share
[fedora@localhost ~]$ ls /mnt/host_share/ -lha
total 0
drwxr-xr-x. 1 fedora fedora 16 Mar 9 11:44 .
drwxr-xr-x. 1 root root 20 Mar 9 11:45 ..
-rw-r--r--. 1 fedora fedora 0 Mar 9 11:44 .gitkeep
J'ai ensuite lancé les commandes suivantes pour installer les packages pour avoir une Fedora Workstation :
$ sudo localectl set-keymap fr-bepo # J'utilise un clavier Bépo
$ sudo dnf update -y
$ sudo dnf install -y @gnome-desktop @workstation-product gnome-session-wayland-session
$ sudo systemctl set-default graphical.target
$ sudo reboot
Et voici le résultat :
Je vais pouvoir intégrer cette méthode à https://github.com/stephane-klein/dotfiles afin de développer et tester mes scripts d'installation chezmoi dans un environnement contrôlé et reproductible, garantissant un comportement déterministe. Desktop configuration as code 🙂.
Le qemu-fedora-workstation-playground contient des scripts pour automatiser les opérations présentées :
/scripts/up.sh/scripts/enter-in-vm.sh/scripts/setup-shared-folder.sh/scripts/install-vm-workstation.sh
Je pense que cette méthode pourra remplacer Vagrant dans plusieurs de mes projets.
Comment tu déploies tes containers Docker en production sans Kubernetes ?
Début novembre un ami me posait la question :
Quand tu déploies des conteneurs en prod, sans k8s, tu fais comment ?
Après 3 mois d'attente, voici ma réponse 🙂.
Mon contexte
Tout d'abord, un peu de contexte. Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Cela dit, j'ai également eu à gérer des infrastructures comportant plusieurs serveurs : 10, 20, 30 serveurs. Ces serveurs étaient généralement utilisés pour héberger une infrastructure de soutien (Platform infrastructure) à destination des développeurs. Par exemple :
- Environnements de recettage
- Serveurs pour faire tourner Gitlab-Runner
- Sauvegarde des données
- Etc.
Ce contexte montre que je n'ai jamais eu à gérer le déploiement de services à très forte charge, comme ceux que l'on trouve sur des plateformes telles que Deezer, le site des impôts, Radio France, Meetic, la Fnac, Cdiscount, France Travail, Blablacar, ou encore Doctolib. La méthode que je décris dans cette note ne concerne pas ce type d'infrastructure.
Ma méthode depuis 2015
Dans cette note, je ne vais pas retracer l'évolution complète de mes méthodes de déploiement, mais plutôt me concentrer sur deux d'entre elles : l'une que j'utilise depuis 2015, et une déclinaison adoptée en 2020.
Voici les principes que j'essaie de suivre et qui constituent le socle de ma doctrine en matière de déploiement de services :
- Je m'efforce de suivre le modèle Baking autant que possible (voir ma note 2025-02-07_1403), sans en faire une approche dogmatique ou extrémiste.
- J'applique les principes de The Twelve-Factors App.
- Je privilégie le paradigme Remote Task Execution, ce qui me permet d'adopter une approche GitOps.
- J'utilise des outils d'orchestration prenant en charge le mode push (voir note 2025-02-07_1612), comme Ansible, et j'évite le mode pull.
En pratique, j'utilise Ansible pour déployer un fichier docker-compose.yml sur le serveur de production et ensuite lancer les services.
Je précise que cette note ne traite pas de la préparation préalable du serveur, de l'installation de Docker, ni d'autres aspects similaires. Afin de ne pas alourdir davantage cette note, je n'aborde pas non plus les questions de Continuous Integration ou de Continuous Delivery.
Imaginons que je souhaite déployer le lecteur RSS Miniflux connecté à un serveur PostgreSQL.
Voici les opérations effectuées par le rôle Ansible à distance sur le serveur de production :
-
- Création d'un dossier
/srv/miniflux/
- Création d'un dossier
-
- Upload de
/srv/miniflux/docker-compose.ymlavec le contenu suivant :
- Upload de
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: password
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:password@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: secret
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
-
- Depuis le dossier
/srv/miniflux/lancement de la commandedocker compose up -d --remove-orphans --wait --pull always
- Depuis le dossier
Voilà, c'est tout 🙂.
En 2020, j'enlève "une couche"
J'aime enlever des couches et en 2020, je me suis demandé si je pouvais pratiquer avec élégance la méthode Remote Execution sans Ansible.
Mon objectif était d'utiliser seulement ssh et un soupçon de Bash.
Voici le résultat de mes expérimentations.
J'ai besoin de deux fichiers.
_payload_deploy_miniflux.shdeploy_miniflux.sh
Voici le contenu de _payload_deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
PROJECT_FOLDER="/srv/miniflux/"
mkdir -p ${PROJECT_FOLDER}
cat <<EOF > ${PROJECT_FOLDER}docker-compose.yaml
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: {{ .Env.MINIFLUX_POSTGRES_PASSWORD }}
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:{{ .Env.MINIFLUX_POSTGRES_PASSWORD }}@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: {{ .Env.MINIFLUX_ADMIN_PASSWORD }}
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
EOF
cd ${PROJECT_FOLDER}
docker compose pull
docker compose up -d --remove-orphans --wait
Voici le contenu de deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
gomplate -f _payload_deploy_miniflux.sh | ssh root@$SERVER1_IP 'bash -s'
J'utilise gomplate pour remplacer dynamiquement les secrets dans le script _payload_deploy_miniflux.sh.
En conclusion, pour déployer une nouvelle version, j'ai juste à exécuter :
$ ./deploy_miniflux.sh
Je trouve cela minimaliste et de plus, l'exécution est bien plus rapide que la solution Ansible.
Ce type de script peut ensuite être exécuté aussi bien manuellement par un développeur depuis sa workstation, que via GitLab-CI ou même Rundeck.
Pour un exemple plus détaillé, consultez ce repository : https://github.com/stephane-klein/poc-bash-ssh-docker-deployement-example
Bien entendu, si vous souhaitez déployer votre propre application que vous développez, vous devez ajouter à cela la partie baking, c'est-à-dire, le docker build qui prépare votre image, l'uploader sur un Docker registry… Généralement je réalise cela avec GitLab-CI/CD ou GitHub Actions.
Objections
Certains DevOps me disent :
- « Mais on ne fait pas ça pour de la production ! Il faut utiliser Kubernetes ! »
- « Comment ! Tu n'utilises pas Kubernetes ? »
Et d'autres :
- « Il ne faut au grand jamais utiliser
docker-composeen production ! »
Ne jamais utiliser docker compose en production ?
J'ai reçu cette objection en 2018. J'ai essayé de comprendre les raisons qui justifiaient que ce développeur considère l'usage de docker compose en production comme un Antipattern.
Si mes souvenirs sont bons, je me souviens que pour lui, la bonne méthode conscistait à déclarer les états des containers à déployer avec le module Ansible docker_container (le lien est vers la version de 2018, depuis ce module s'est grandement amélioré).
Je n'ai pas eu plus d'explications 🙁.
J'ai essayé d'imaginer ses motivations.
J'en ai trouvé une que je ne trouve pas très pertinente :
- Uplodaer un fichier
docker-compose.ymlen production pour ensuite lancer des fonctions distantes sur celui-ci est moins performant que manipulerdocker-engineà distance.
J'en ai imaginé une valable :
- En déclarant la configuration de services Docker uniquement dans le rôle Ansible cela garantit qu'aucun développeur n'ira modifier et manipuler directement le fichier
docker-compose.ymlsur le serveur de production.
Je trouve que c'est un très bon argument 👍️.
Cependant, cette méthode a à mes yeux les inconvénients suivants :
- Je maitrise bien mieux la syntaxe de docker compose que la syntaxe du module Ansible community.docker.docker_container
- J'utilise docker compose au quotidien sur ma workstation et je n'ai pas envie d'apprendre une syntaxe supplémentaire uniquement pour le déploiement.
- Je pense que le nombre de développeurs qui maîtrisent docker compose est suppérieur au nombre de ceux qui maîtrisent le module Ansible
community.docker.docker_container. - Je ne suis pas utilisateur maximaliste de la méthode Remote Execution. Dans certaines circonstances, je trouve très pratique de pouvoir manipuler docker compose dans une session ssh directement sur un serveur. En période de stress ou de debug compliqué, je trouve cela pratique. J'essaie d'être assez rigoureux pour ne pas oublier de reporter mes changements effectués directement le serveur dans les scripts de déploiements (configuration as code).
Tu dois utiliser Kubernetes !
Alors oui, il y a une multitude de raisons valables d'utiliser Kubernetes. C'est une technologie très puissante, je n'ai pas le moindre doute à ce sujet.
J'ai une expérience dans ce domaine, ayant utilisé Kubernetes presque quotidiennement dans un cadre professionnel de janvier 2016 à septembre 2017. J'ai administré un petit cluster auto-managé composé de quelques nœuds et y ai déployé diverses applications.
Ceci étant dit, je rappelle mon contexte :
Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Je pense que faire appel à Kubernetes dans ce contexte est de l'overengineering.
Je dois avouer que j'envisage d'expérimenter un usage minimaliste de K3s (attention au "3", je n'ai pas écrit k8s) pour mes déploiements. Mais je sais que Kubernetes est un rabbit hole : Helm, Kustomize, Istio, Helmfile, Grafana Tanka… J'ai peur de tomber dans un Yak!.
D'autre part, il existe déjà un pourcentage non négligeable de développeur qui ne maitrise ni Docker, ni docker compose et dans ces conditions, faire le choix de Kubernetes augmenterait encore plus la barrière à l'entrée permettant à des collègues de pouvoir comprendre et intervenir sur les serveurs d'hébergement.
C'est pour cela que ma doctrine d'artisan développeur consiste à utiliser Kubernetes seulement à partir du moment où je rencontre des besoins de forte charge, de scalabilité.
Journal du mardi 04 février 2025 à 16:46
Je souhaite créer un playground d'un development kit pour Python + PostgreSQL (via Docker) + Flask + Flask-Migrate, basé sur Mise.
J'ai la contrainte suivante : le development kit doit fonctionner sous MS Windows !
Je me dis que c'est une bonne occasion pour moi de tester Windows Subsystem for Linux 🙂.
Problème : je ne possède pas d'instance MS Windows.
#JaiDécouvert que depuis 2015, Microsoft met à disposition des ISOs officiels de MS Windows :
- ISO pour Windows 10 : https://www.microsoft.com/fr-fr/software-download/windows10ISO
- ISO pour Windows 11 : https://www.microsoft.com/fr-fr/software-download/windows11
- Virtual machine MS Windows pour VirtualBox et d'autres : https://developer.microsoft.com/en-us/windows/downloads/virtual-machines/
J'ai testé dans ce playground le lancement d'une Virtual machine MS Windows avec Vagrant : https://github.com/stephane-klein/vagrant-windows-playground.
Cela a bien fonctionné 🙂.
J'ai aussi découvert le repository windows-vagrant qui semble permettre de construire différents types d'images MS Windows avec Packer. Je n'ai pas essayé d'en construire une.
Journal du dimanche 19 janvier 2025 à 11:24
#iteration Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram :
Être capable d'exposer sur Internet un port d'une VM.
Voici comment j'ai atteint cet objectif.
Pour faire ce test, j'ai installé un serveur http nginx sur une VM qui a l'IP 192.168.1.236.
Cette IP est attribuée par le DHCP installé sur mon routeur OpenWrt. Le serveur hôte Proxmox est configuré en mode bridge.
Ma Box Internet Bouygues sur 192.168.1.254 peut accéder directement à cette VM 192.168.1.236.
Pour exposer le serveur Proxmox sur Internet, j'ai configuré mon serveur Serveur NUC i3 gen 5 en tant que DMZ host.
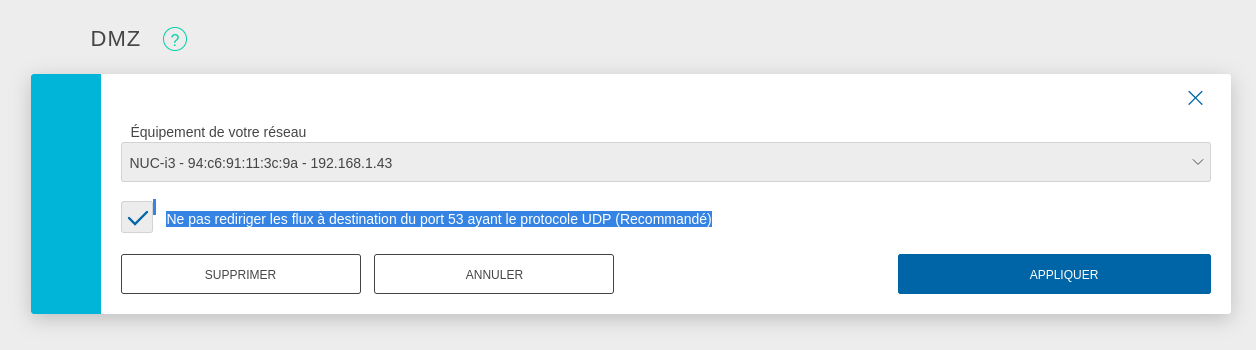
J'ai suivi la recommandation pour éviter une attaque du type : DNS amplification attacks
DNS amplification attacks involves an attacker sending a DNS name lookup request to one or more public DNS servers, spoofing the source IP address of the targeted victim.
Avec cette configuration, je peux accéder en ssh au Serveur NUC i3 gen 5 depuis Internet.
J'ai tout de suite décidé d'augmenter la sécurité du serveur ssh :
# cat <<'EOF' > /etc/ssh/sshd_config.d/sklein.conf
Protocol 2
PasswordAuthentication no
PubkeyAuthentication yes
AuthenticationMethods publickey
KbdInteractiveAuthentication no
X11Forwarding no
# systemctl restart ssh
J'ai ensuite configuré le firewall basé sur nftables pour mettre en place quelques règles de sécurité et mettre en place de redirection de port du serveur hôte Proxmox vers le port 80 de la VM 192.168.1.236.
nftables est installé par défaut sur Proxmox mais n'est pas activé. Je commence par activer nftables :
root@nuci3:~# systemctl enable nftables
root@nuci3:~# systemctl start nftables
Voici ma configuration /etc/nftables.conf, je me suis fortement inspiré des exemples présents dans ArchWiki : https://wiki.archlinux.org/title/Nftables#Server
# cat <<'EOF' > /etc/nftables.conf
flush ruleset;
table inet filter {
# Configuration from https://wiki.archlinux.org/title/Nftables#Server
set LANv4 {
type ipv4_addr
flags interval
elements = { 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16, 169.254.0.0/16 }
}
set LANv6 {
type ipv6_addr
flags interval
elements = { fd00::/8, fe80::/10 }
}
chain input {
type filter hook input priority filter; policy drop;
iif lo accept comment "Accept any localhost traffic"
ct state invalid drop comment "Drop invalid connections"
ct state established,related accept comment "Accept traffic originated from us"
meta l4proto ipv6-icmp accept comment "Accept ICMPv6"
meta l4proto icmp accept comment "Accept ICMP"
ip protocol igmp accept comment "Accept IGMP"
udp dport mdns ip6 daddr ff02::fb accept comment "Accept mDNS"
udp dport mdns ip daddr 224.0.0.251 accept comment "Accept mDNS"
ip saddr @LANv4 accept comment "Connections from private IP address ranges"
ip6 saddr @LANv6 accept comment "Connections from private IP address ranges"
tcp dport ssh accept comment "Accept SSH on port 22"
tcp dport 8006 accept comment "Accept Proxmox web console"
udp sport bootpc udp dport bootps ip saddr 0.0.0.0 ip daddr 255.255.255.255 accept comment "Accept DHCPDISCOVER (for DHCP-Proxy)"
}
chain forward {
type filter hook forward priority filter; policy accept;
}
chain output {
type filter hook output priority filter; policy accept;
}
}
table nat {
chain prerouting {
type nat hook prerouting priority dstnat;
tcp dport 80 dnat to 192.168.1.236;
}
chain postrouting {
type nat hook postrouting priority srcnat;
masquerade
}
}
EOF
Pour appliquer en toute sécurité cette configuration, j'ai suivi la méthode indiquée dans : "Appliquer une configuration nftables avec un rollback automatique de sécurité".
Après cela, voici les tests que j'ai effectués :
- Depuis mon réseau local :
- Test d'accès au serveur Proxmox via ssh :
ssh root@192.168.1.43 - Test d'accès au serveur Proxmox via la console web : https://192.168.1.43:8006
- Test d'accès au service http dans la VM :
curl -I http://192.168.1.236
- Test d'accès au serveur Proxmox via ssh :
- Depuis Internet :
Voilà, tout fonctionne correctement 🙂.
Prochaines étapes :
- Être capable d'accéder depuis Internet via IPv6 à une VM
- Je souhaite arrive à effectuer un déploiement d'une Virtual instance via Terraform
Journal du lundi 23 décembre 2024 à 19:39
J'ai commencé le Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram le 9 octobre.
Le 27 octobre, j'ai publié la note 2024-10-27_2109 qui contient une erreur qui m'a fait perdre 14h !
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
[ 0.0] Examining the guest ...
[ 4.5] Setting a random seed
virt-customize: warning: random seed could not be set for this type of
guest
[ 4.5] Setting the machine ID in /etc/machine-id
[ 4.5] Installing packages: qemu-guest-agent
[ 32.1] Running: systemctl enable qemu-guest-agent.service
[ 32.6] Finishing off
Je n'avais pas fait attention au message Setting the machine ID in /etc/machine-id 🙊.
Conséquence : le template Proxmox Ubuntu contenait un fichier /etc/machine-id avec un id.
Conséquence : toutes les Virtual machine que je créais sous Proxmox avaient la même valeur machine-id.
J'ai découvert que l'option 61 "Client identifier" du protocole DHCP permet de passer un client id au serveur DHCP qui sera utilisé à la place de l'adresse MAC.
Conséquence : le serveur DHCP assignait la même IP à ces Virtual machine.
J'ai pensé que le serveur DHCP de mon router BBox avait un problème. J'ai donc décidé d'installer Projet 15 - Installation et configuration de OpenWrt sur Xiaomi Mi Router 4A Gigabit pour avoir une meilleure maitrise du serveur DHCP.
Problème : j'ai fait face au même problème avec le serveur DHCP de OpenWrt.
Après quelques recherches, j'ai découvert que contrairement à virt-customize la commande virt-sysprep permet d'agir sur des images qui ont vocation à être clonées.
"Sysprep" stands for "system preparation" tool. The name comes from the Microsoft program sysprep.exe which is used to unconfigure Windows machines in preparation for cloning them.
Pour corriger le problème, j'ai remplacé cette ligne :
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
Par ces deux lignes :
# virt-sysprep -a noble-server-cloudimg-amd64.img --network --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
# virt-sysprep --operation machine-id -a noble-server-cloudimg-amd64.img
La seconde commande permet de supprimer le fichier /etc/machine-id, ce qui corrige le problème d'attribution d'IP par le serveur DHCP.
À noter que je ne comprends pas pourquoi il est nécessaire de lancer explicitement cette seconde commande, étant donné que la commande virt-sysprep est destinée aux images de type "template". Le fichier /etc/machine-id ne devrait jamais être créé, ou tout du moins, automatiquement supprimé à la fin de chaque utilisation de virt-sysprep.
Maintenant, l'instanciation de Virtual machine fonctionne bien, elles ont des IP différentes 🙂.
Prochaine étape du Projet GH-271 :
Je souhaite arrive à effectuer un déploiement d'une Virtual instance via cli de Terraform.
Journal du dimanche 27 octobre 2024 à 21:09
Nouvelle #iteration du Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram.
J'ai eu des difficultés à trouver comment déployer avec Proxmox des Virtual instance basées sur Ubuntu Cloud Image.
J'ai trouvé réponse à mes questions dans cet article : "Perfect Proxmox Template with Cloud Image and Cloud Init".
Mais depuis, j'ai trouvé un meilleur tutoriel : "Linux VM Templates in Proxmox on EASY MODE using Prebuilt Cloud Init Images!".
Création d'un template Ubuntu LTS
J'ai exécuté les commandes suivantes en SSH sur mon serveur NUC i3 pour créer un template de VM Proxmox.
root@nuci3:~# apt update -y && apt install libguestfs-tools jq -y
root@nuci3:~# wget https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img
Ancienne commande qui contient une erreur à ne pas utilisé, plus d'information dans la note 2024-12-23_1939 :
root@nuci3:~# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
root@nuci3:~# virt-sysprep -a noble-server-cloudimg-amd64.img --network --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
root@nuci3:~# virt-sysprep --operation machine-id -a noble-server-cloudimg-amd64.img
root@nuci3:~# qm create 8000 --memory 2048 --core 2 --name ubuntu-cloud-template --net0 virtio,bridge=vmbr0
root@nuci3:~# qm disk import 8000 noble-server-cloudimg-amd64.img local-lvm
transferred 3.5 GiB of 3.5 GiB (100.00%)
transferred 3.5 GiB of 3.5 GiB (100.00%)
Successfully imported disk as 'unused0:local-lvm:vm-8000-disk-0'
root@nuci3:~# rm noble-server-cloudimg-amd64.img
root@nuci3:~# qm set 8000 --scsihw virtio-scsi-pci --scsi0 local-lvm:vm-8000-disk-0
update VM 8000: -scsi0 local-lvm:vm-8000-disk-0 -scsihw virtio-scsi-pci
root@nuci3:~# qm set 8000 --ide2 local-lvm:cloudinit
update VM 8000: -ide2 local:cloudinit
Formatting '/var/lib/vz/images/8000/vm-8000-cloudinit.qcow2', fmt=qcow2 cluster_size=65536 extended_l2=off preallocation=metadata compression_type=zlib size=4194304 lazy_refcounts=off refcount_bits=16
ide2: successfully created disk 'local:8000/vm-8000-cloudinit.qcow2,media=cdrom'
generating cloud-init ISO
(liste des paramètres cloud-init)
root@nuci3:~# qm set 8000 --ipconfig0 "ip6=auto,ip=dhcp"
root@nuci3:~# qm set 8000 --sshkeys ~/.ssh/authorized_keys
root@nuci3:~# qm set 8000 --ciuser stephane
root@nuci3:~# qm set 8000 --cipassword password # optionnel, seulement en phase de debug
root@nuci3:~# qm set 8000 --boot c --bootdisk scsi0
update VM 8000: -boot c -bootdisk scsi0
root@nuci3:~# qm set 8000 --serial0 socket --vga serial0
update VM 8000: -serial0 socket -vga serial0
root@nuci3:~# qm set 8000 --agent enabled=1
root@nuci3:~# qm set 8000 --ciupgrade 0
root@nuci3:~# qm template 8000
Renamed "vm-8000-disk-0" to "base-8000-disk-0" in volume group "pve"
Logical volume pve/base-8000-disk-0 changed.
WARNING: Combining activation change with other commands is not advised.
Création d'une Virtual Instance
root@nuci3:~# qm clone 8000 100 --name server1
root@nuci3:~# qm start 100
root@nuci3:~# qm guest cmd 100 network-get-interfaces | jq -r '.[] | select(.name == "eth0") | .["ip-addresses"][0] | .["ip-address"]'
192.168.1.64
$ ssh stephane@192.168.1.64
The authenticity of host '192.168.1.64 (192.168.1.64)' can't be established.
ED25519 key fingerprint is SHA256:OJHcY3GHOsm3I4qcsYFc6V4qePNxVS4iAOBsDjeLM7o.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '192.168.1.64' (ED25519) to the list of known hosts.
Welcome to Ubuntu 24.04.1 LTS (GNU/Linux 6.8.0-45-generic x86_64)
...